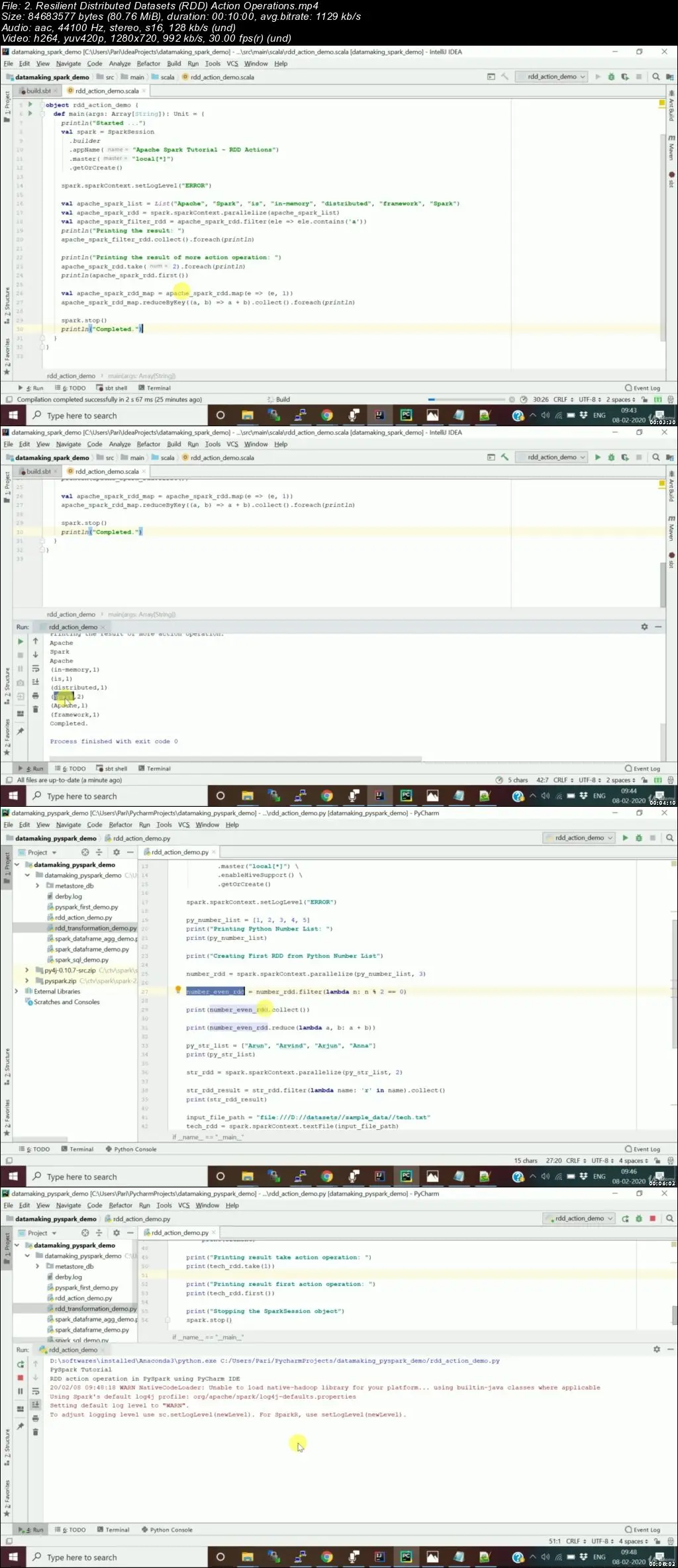
Spark Project on Cloudera Hadoop(CDH) and GCP for Beginners

Spark Project on Cloudera Hadoop(CDH) and GCP for Beginners
Video: .mp4 (1280x720, 30 fps(r)) | Audio: aac, 44100 Hz, 2ch | Size: 4.43 GB
Genre: eLearning Video | Duration: 46 lectures (10 hour, 53 mins) | Language: English
Video: .mp4 (1280x720, 30 fps(r)) | Audio: aac, 44100 Hz, 2ch | Size: 4.43 GB
Genre: eLearning Video | Duration: 46 lectures (10 hour, 53 mins) | Language: English
Building Data Processing Pipeline Using Apache NiFi, Apache Kafka, Apache Spark, Cassandra, MongoDB, Hive and Zeppelin
What you'll learn
Complete Spark Project Development on Cloudera Hadoop and Spark Cluster
Fundamentals of Google Cloud Platform(GCP)
Setting up Cloudera Hadoop and Spark Cluster(CDH 6.3) on GCP
Features of Spark Structured Streaming using Spark with Scala
Features of Spark Structured Streaming using Spark with Python(PySpark)
Fundamentals of Apache NiFi
Fundamentals of Apache Kafka
How to use NoSQL like MongoDB and Cassandra with Spark Structured Streaming
How to build Data Visualisation using Python
Fundamentals of Apache Hive and how to integrate with Apache Spark
Features of Apache Zeppelin
Fundamentals of Docker and Containerization
Requirements
Basic understanding of Programming Language
Basic understanding of Apache Hadoop
Basic understanding of Apache Spark
No worry, even solid Apache Hadoop and Apache Spark basics are covered for the benefit of absolute beginners
Most important one, which is willingness to learn
Description
In retail business, retail stores and eCommerce websites generates large amount of data in real-time.
There is always a need to process these data in real-time and generate insights which will be used by the business people and they make business decision to increase the sales in the retail market and provide better customer experience.
Since the data is huge and coming in real-time, we need to choose the right architecture with scalable storage and computation frameworks/technologies.
Hence we want to build the Data Processing Pipeline Using Apache NiFi, Apache Kafka, Apache Spark, Apache Cassandra, MongoDB, Apache Hive and Apache Zeppelin to generate insights out of this data.
The Spark Project is built using Apache Spark with Scala and PySpark on Cloudera Hadoop(CDH 6.3) Cluster which is on top of Google Cloud Platform(GCP).
Who this course is for:
Beginners who want to learn Apache Spark/Big Data Project Development Process and Architecture
Entry/Intermediate level Data Engineers and Data Scientist
Data Engineering and Data Science Aspirants
Data Enthusiast who want to learn, how to develop and run Spark Application on CDH Cluster
Anyone who is really willingness to become Big Data/Spark Developer
Spark Project on Cloudera Hadoop(CDH) and GCP for Beginners