Real Time Spark Project for Beginners: Hadoop, Spark, Docker
Real Time Spark Project for Beginners: Hadoop, Spark, Docker
Duration: 6h 34m | .MP4 1280x720, 30 fps(r) | AAC, 44100 Hz, 2ch | 3.78 GB
Genre: eLearning | Language: English
Duration: 6h 34m | .MP4 1280x720, 30 fps(r) | AAC, 44100 Hz, 2ch | 3.78 GB
Genre: eLearning | Language: English
Building Real Time Data Pipeline Using Apache Kafka, Apache Spark, Hadoop, PostgreSQL, Django and Flexmonster on Docker
What you'll learn
Complete Development of Real Time Streaming Data Pipeline using Hadoop and Spark Cluster on Docker
Setting up Single Node Hadoop and Spark Cluster on Docker
Features of Spark Structured Streaming using Spark with Scala
Features of Spark Structured Streaming using Spark with Python(PySpark)
How to use PostgreSQL with Spark Structured Streaming
Basic understanding of Apache Kafka
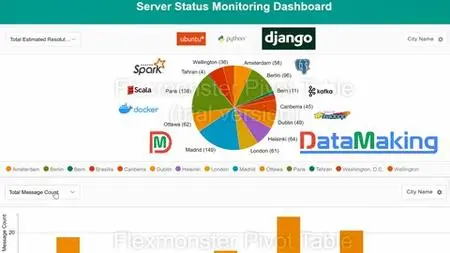
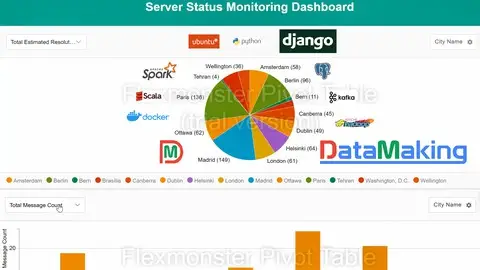
How to build Data Visualisation using Django Web Framework and Flexmonster
Fundamentals of Docker and Containerization
Requirements
Basic understanding of Programming Language
Basic understanding of Apache Hadoop
Basic understanding of Apache Spark
Description
In many data centers, different type of servers generate large amount of data(events, Event in this case is status of the server in the data center) in real-time.
There is always a need to process these data in real-time and generate insights which will be used by the server/data center monitoring people and they have to track these server's status regularly and find the resolution in case of issues occurring, for better server stability.
Since the data is huge and coming in real-time, we need to choose the right architecture with scalable storage and computation frameworks/technologies.
Hence we want to build the Real Time Data Pipeline Using Apache Kafka, Apache Spark, Hadoop, PostgreSQL, Django and Flexmonster on Docker to generate insights out of this data.
The Spark Project/Data Pipeline is built using Apache Spark with Scala and PySpark on Apache Hadoop Cluster which is on top of Docker.
Data Visualization is built using Django Web Framework and Flexmonster.
Who this course is for:
Beginners who want to learn Apache Spark/Big Data Project Development Process and Architecture
Beginners who want to learn Real Time Streaming Data Pipeline Development Process and Architecture
Entry/Intermediate level Data Engineers and Data Scientist
Data Engineering and Data Science Aspirants
Data Enthusiast who want to learn, how to develop and run Spark Application on Docker
Anyone who is really willingness to become Big Data/Spark Developer
More Info
Real Time Spark Project for Beginners: Hadoop, Spark, Docker