Indexing Data in Elasticsearch

Indexing Data in Elasticsearch
MP4 | Video: AVC 1280x720 | Audio: AAC 44KHz 2ch | Duration: 2 Hours 46M | 310 MB
Genre: eLearning | Language: English
MP4 | Video: AVC 1280x720 | Audio: AAC 44KHz 2ch | Duration: 2 Hours 46M | 310 MB
Genre: eLearning | Language: English
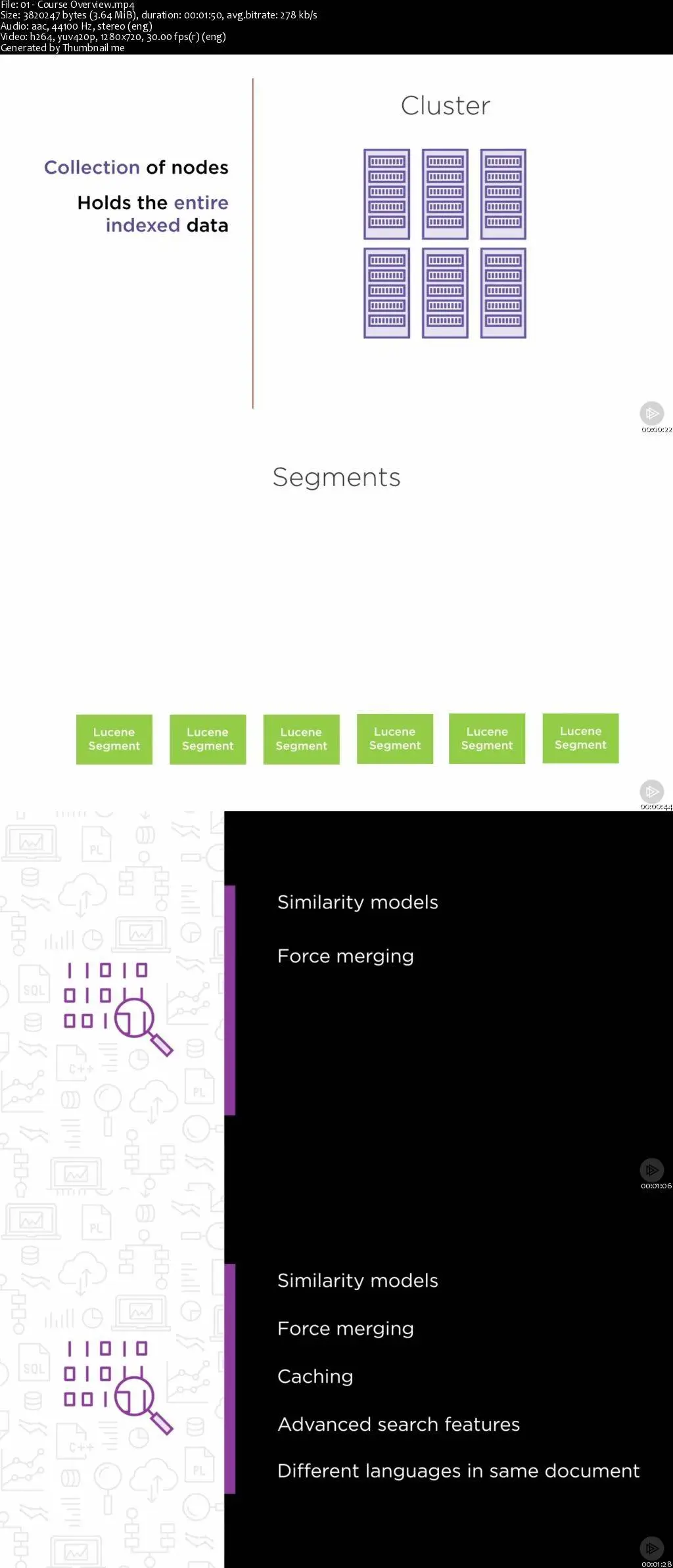
This course explains the index distribution architecture of Elasticsearch, cluster configuration, shards and replicas, similarity models, advanced search, and mixed-language documents, all of which improve the performance of search queries.
Getting Elasticsearch up and running is very simple, but tuning it to have low latency and high performance for search queries requires a deep understanding of the index distribution architecture. In this course, Indexing Data in Elasticsearch, you will understand the structure of distributed indices and advanced search constructs such as similarity models, segment merging, suggesters, fuzzy searches and working with mixed-language documents. First, you will study why shard overallocation is a good thing and how you can configure your cluster to avoid the split-brain scenario. Then, you will see how indices can be configured to use different similarity models and how to use force merging of segments to improve the performance of large indices. Next, you will explore how to cache prudently and use advanced search features. Finally, you will learn to deal with different languages in the same document with the ICU plugin. At the end of this course, you will have a deep understanding of how indexing works in Elasticsearch and be comfortable with advanced query constructs.

Indexing Data in Elasticsearch