Handling Batch Data with Apache Spark on Databricks
Handling Batch Data with Apache Spark on Databricks
.MP4, AVC, 1280x720, 30 fps | English, AAC, 2 Ch | 2h 21m | 275 MB
Instructor: Janani Ravi
.MP4, AVC, 1280x720, 30 fps | English, AAC, 2 Ch | 2h 21m | 275 MB
Instructor: Janani Ravi
This course will teach you how to transform and aggregate batch data using Apache Spark on the Azure Databricks platform using selection, filter, and aggregation queries, built-in and user-defined functions, and perform windowing and join operations on batch data.
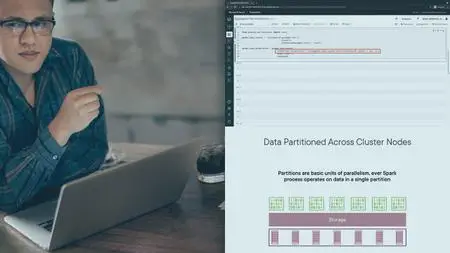
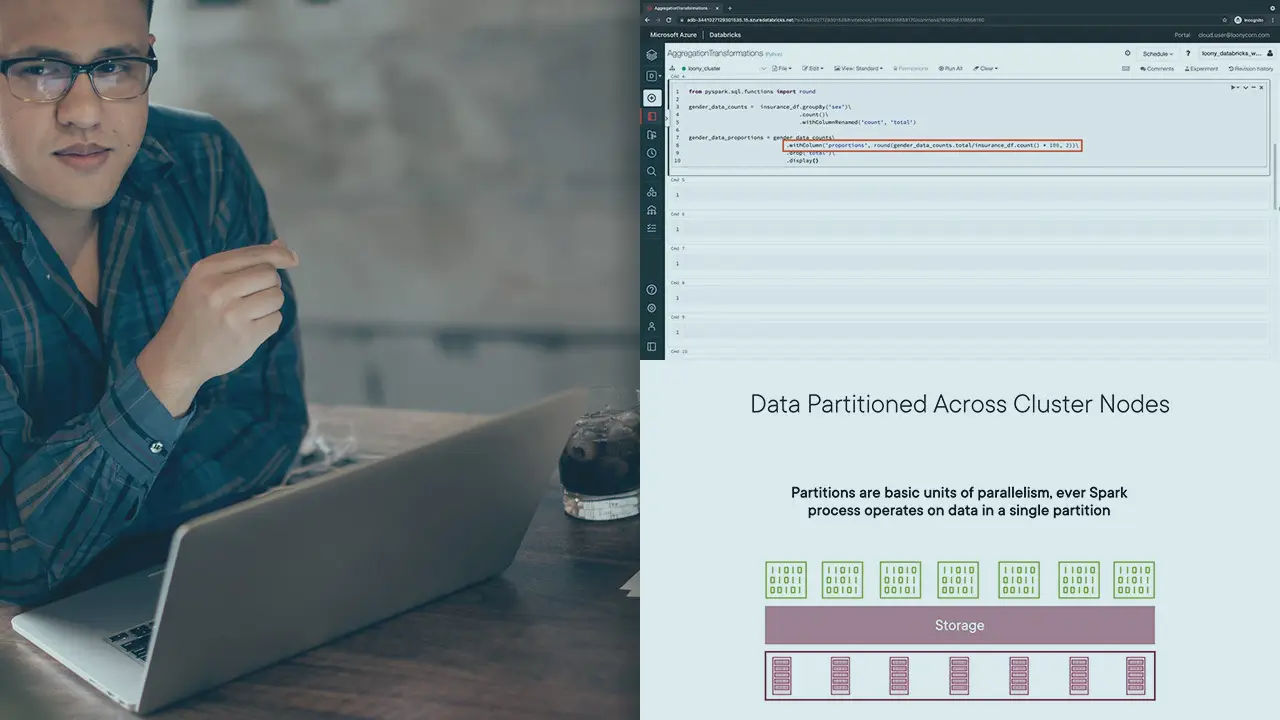
Azure Databricks allows you to work with big data processing and queries using the Apache Spark unified analytics engine. Azure Databricks allows to work with a variety of batch sources and makes it seamless to analyze, visualize, and process data on the Azure Cloud Platform. In this course, Handling Batch Data with Apache Spark on Databricks, you will learn how to perform transformations and aggregations on batch data with selection, filtering, grouping, and ordering queries that use the DataFrame API. You will understand the difference between narrow transformations and wide transformations in Spark which will help you figure out why certain transformations are more efficient than others. You will also see how you can execute these same transformations by executing SQL queries on your data. Next, you will learn how you can implement your own custom user-defined functions to process your data. You will write code on Azure Databricks notebooks to define and register your UDFs and use them to transform your data. You will also understand how to define and use different flavors of vectorized UDFs for data processing and learn how vectorized UDFs are often more efficient than regular UDFs. Along the way, you will also see how you can read from Azure Cosmos DB as a source for your batch data. Finally, you will see how you can repartition your data in memory to improve processing performance, you will use window functions to compute statistics on your data and you will combine data frames using union and join operations. When you’re finished with this course you will have the skills and ability to perform advanced transformations and aggregations on batch data, including defining and using user-defined functions for processing.
Handling Batch Data with Apache Spark on Databricks