Foundational Math for Generative AI: Understanding LLMs and Transformers through Practical Applications

Foundational Math for Generative AI: Understanding LLMs and Transformers through Practical Applications
.MP4, AVC, 1280x720, 30 fps | English, AAC, 2 Ch | 2h 58m | 411 MB
Instructor: Axel Sirota
.MP4, AVC, 1280x720, 30 fps | English, AAC, 2 Ch | 2h 58m | 411 MB
Instructor: Axel Sirota
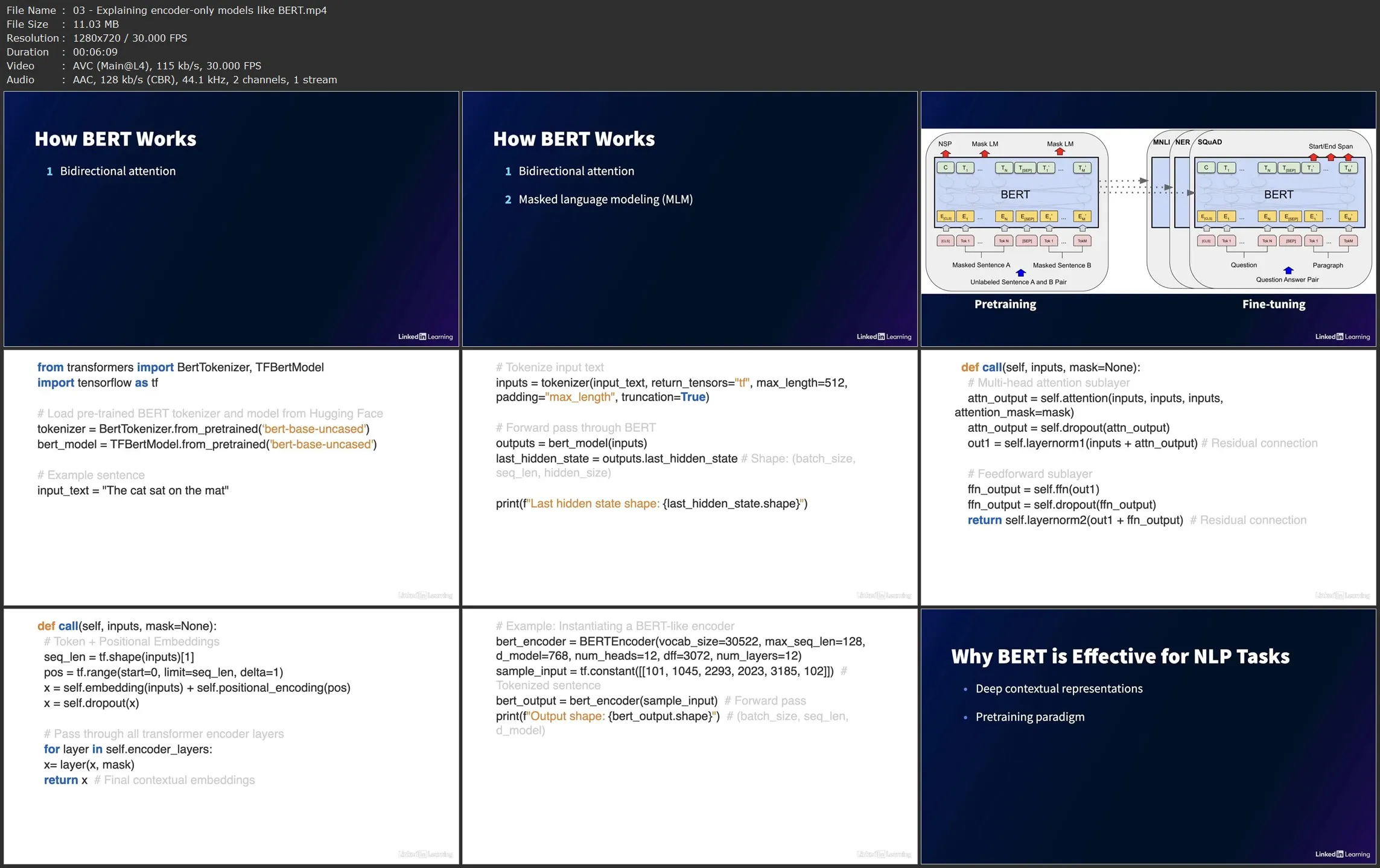
Unlock the mysteries behind the models powering today’s most advanced AI applications. In this course, instructor Axel Sirota takes you beyond just using large language models (LLMs) like BERT or GPT and highlights the mathematical foundations of generative AI. Explore the challenge of sentiment analysis with simple recurrent neural networks (RNNs) and progressively evolve your approach as you gain a deep understanding of attention mechanisms, transformers, and models.
Through intuitive explanations and hands-on coding exercises, Axel outlines why attention revolutionized natural language processing, and how transformers reshaped the field by eliminating the need for RNNs altogether. Along the way, get tips on fine-tuning pretrained models, applying cutting-edge techniques like low-rank adaptation (LoRA), and leveraging your newly acquired skills to build smarter, more efficient models and innovate in the fast-evolving world of AI.
Learning objectives
- Gain an intuitive understanding of how and why LLMs and transformers work.
- Learn how attention mechanisms evolved to solve key problems in RNN-based models.
- Develop a sentiment analysis model using TensorFlow, Keras, and Hugging Face’s DistilBERT.
- Enhance models progressively with mathematical insights applied in code, from word embeddings to attention and transformer layers.
- Use visualizations to grasp how attention and optimization work.
Foundational Math for Generative AI: Understanding LLMs and Transformers through Practical Applications