


AppliedAICourse - Applied Machine Learning Course

AppliedAICourse - Applied Machine Learning Course
WEBRip | English | MP4 | 1280 x 720 | AVC ~89.2 kbps | 24 fps
AAC | 126 Kbps | 44.1 KHz | 2 channels | ~150 hours | 25.37 GB
Genre: Video Tutorial
WEBRip | English | MP4 | 1280 x 720 | AVC ~89.2 kbps | 24 fps
AAC | 126 Kbps | 44.1 KHz | 2 channels | ~150 hours | 25.37 GB
Genre: Video Tutorial
Applied AI course (AAIC Technologies Pvt. Ltd.) is an Ed-Tech company based out in Hyderabad offering on-line training in Machine Learning and Artificial intelligence. Applied AI course through its unparalleled curriculum aims to bridge the gap between industry requirements and skill set of aspiring candidates by churning out highly skilled machine learning professionals who are well prepared to tackle real world business problems.The Machine Learning course that gets you HIRED!
No prerequisites
24*7 customer service
140+ hours of content
12+ real world case studies
Case Studies in Machine Learning Course
Content:
1.1 - How to Learn from Appliedaicourse
1.2 - How the Job Guarantee program works
10.1 - Why learn it
10.10 - Hyper Cube,Hyper Cuboid
10.11 - Revision Questions
10.2 - Introduction to Vectors(2-D, 3-D, n-D) , Row Vector and Column Vector
10.3 - Dot Product and Angle between 2 Vectors
10.4 - Projection and Unit Vector
10.5 - Equation of a line (2-D), Plane(3-D) and Hyperplane (n-D), Plane Passing through origin, Normal to a Plane
10.6 - Distance of a point from a PlaneHyperplane, Half-Spaces
10.7 - Equation of a Circle (2-D), Sphere (3-D) and Hypersphere (n-D)
10.8 - Equation of an Ellipse (2-D), Ellipsoid (3-D) and Hyperellipsoid (n-D)
10.9 - Square ,Rectangle
11.1 - Introduction to Probability and Statistics
11.10 - How distributions are used
11.11 - Chebyshev’s inequality
11.12 - Discrete and Continuous Uniform distributions
11.13 - How to randomly sample data points (Uniform Distribution)
11.14 - Bernoulli and Binomial Distribution
11.15 - Log Normal Distribution
11.16 - Power law distribution
11.17 - Box cox transform
11.18 - Applications of non-gaussian distributions
11.19 - Co-variance
11.2 - Population and Sample
11.20 - Pearson Correlation Coefficient
11.21 - Spearman Rank Correlation Coefficient
11.22 - Correlation vs Causation
11.23 - How to use correlations
11.24 - Confidence interval (C.I) Introduction
11.25 - Computing confidence interval given the underlying distribution
11.26 - C.I for mean of a normal random variable
11.27 - Confidence interval using bootstrapping
11.28 - Hypothesis testing methodology, Null-hypothesis, p-value
11.29 - Hypothesis Testing Intution with coin toss example
11.3 - GaussianNormal Distribution and its PDF(Probability Density Function)
11.30 - Resampling and permutation test
11.31 - K-S Test for similarity of two distributions
11.32 - Code Snippet K-S Test
11.33 - Hypothesis testing another example
11.34 - Resampling and Permutation test another example
11.35 - How to use hypothesis testing
11.36 - Proportional Sampling
11.37 - Revision Questions
11.4 - CDF(Cumulative Distribution function) of GaussianNormal distribution
11.5 - Symmetric distribution, Skewness and Kurtosis
11.6 - Standard normal variate (Z) and standardization
11.7 - Kernel density estimation
11.8 - Sampling distribution & Central Limit theorem
11.9 - Q-Q plotHow to test if a random variable is normally distributed or not
12.1 - Questions & Answers
13.1 - What is Dimensionality reduction
13.10 - Code to Load MNIST Data Set
13.2 - Row Vector and Column Vector
13.3 - How to represent a data set
13.4 - How to represent a dataset as a Matrix
13.5 - Data Preprocessing Feature Normalisation
13.6 - Mean of a data matrix
13.7 - Data Preprocessing Column Standardization
13.8 - Co-variance of a Data Matrix
13.9 - MNIST dataset (784 dimensional)
14.1 - Why learn PCA
14.10 - PCA for dimensionality reduction (not-visualization)
14.2 - Geometric intuition of PCA
14.3 - Mathematical objective function of PCA
14.4 - Alternative formulation of PCA Distance minimization
14.5 - Eigen values and Eigen vectors (PCA) Dimensionality reduction
14.6 - PCA for Dimensionality Reduction and Visualization
14.7 - Visualize MNIST dataset
14.8 - Limitations of PCA
14.9 - PCA Code example
15.1 - What is t-SNE
15.2 - Neighborhood of a point, Embedding
15.3 - Geometric intuition of t-SNE
15.4 - Crowding Problem
15.5 - How to apply t-SNE and interpret its output
15.6 - t-SNE on MNIST
15.7 - Code example of t-SNE
15.8 - Revision Questions
16.1 - Questions & Answers
17.1 - Dataset overview Amazon Fine Food reviews(EDA)
17.10 - Avg-Word2Vec, tf-idf weighted Word2Vec
17.11 - Bag of Words( Code Sample)
17.12 - Text Preprocessing( Code Sample)
17.13 - Bi-Grams and n-grams (Code Sample)
17.14 - TF-IDF (Code Sample)
17.15 - Word2Vec (Code Sample)
17.16 - Avg-Word2Vec and TFIDF-Word2Vec (Code Sample)
17.17 - Assignment-2 Apply t-SNE
17.2 - Data Cleaning Deduplication
17.3 - Why convert text to a vector
17.4 - Bag of Words (BoW)
17.5 - Text Preprocessing Stemming
17.6 - uni-gram, bi-gram, n-grams
17.7 - tf-idf (term frequency- inverse document frequency)
17.8 - Why use log in IDF
17.9 - Word2Vec
18.1 - How “Classification” works
18.10 - KNN Limitations
18.11 - Decision surface for K-NN as K changes
18.12 - Overfitting and Underfitting
18.13 - Need for Cross validation
18.14 - K-fold cross validation
18.15 - Visualizing train, validation and test datasets
18.16 - How to determine overfitting and underfitting
18.17 - Time based splitting
18.18 - k-NN for regression
18.19 - Weighted k-NN
18.2 - Data matrix notation
18.20 - Voronoi diagram
18.21 - Binary search tree
18.22 - How to build a kd-tree
18.23 - Find nearest neighbours using kd-tree
18.24 - Limitations of Kd tree
18.25 - Extensions
18.26 - Hashing vs LSH
18.27 - LSH for cosine similarity
18.28 - LSH for euclidean distance
18.29 - Probabilistic class label
18.3 - Classification vs Regression (examples)
18.30 - Code SampleDecision boundary
18.31 - Code SampleCross Validation
18.32 - Revision Questions
18.4 - K-Nearest Neighbours Geometric intuition with a toy example
18.5 - Failure cases of KNN
18.6 - Distance measures Euclidean(L2) , Manhattan(L1), Minkowski, Hamming
18.7 - Cosine Distance & Cosine Similarity
18.8 - How to measure the effectiveness of k-NN
18.9 - TestEvaluation time and space complexity
19.1 - Questions & Answers
2.1 - Python, Anaconda and relevant packages installations
2.10 - Control flow for loop
2.11 - Control flow break and continue
2.2 - Why learn Python
2.3 - Keywords and identifiers
2.4 - comments, indentation and statements
2.5 - Variables and data types in Python
2.6 - Standard Input and Output
2.7 - Operators
2.8 - Control flow if else
2.9 - Control flow while loop
20.1 - Introduction
20.10 - Local reachability-density(A)
20.11 - Local outlier Factor(A)
20.12 - Impact of Scale & Column standardization
20.13 - Interpretability
20.14 - Feature Importance and Forward Feature selection
20.15 - Handling categorical and numerical features
20.16 - Handling missing values by imputation
20.17 - curse of dimensionality
20.18 - Bias-Variance tradeoff
20.19 - Intuitive understanding of bias-variance
20.2 - Imbalanced vs balanced dataset
20.20 - Revision Questions
20.21 - best and wrost case of algorithm
20.3 - Multi-class classification
20.4 - k-NN, given a distance or similarity matrix
20.5 - Train and test set differences
20.6 - Impact of outliers
20.7 - Local outlier Factor (Simple solution Mean distance to Knn)
20.8 - k distance
20.9 - Reachability-Distance(A,B)
21.1 - Accuracy
21.10 - Revision Questions
21.2 - Confusion matrix, TPR, FPR, FNR, TNR
21.3 - Precision and recall, F1-score
21.4 - Receiver Operating Characteristic Curve (ROC) curve and AUC
21.5 - Log-loss
21.6 - R-SquaredCoefficient of determination
21.7 - Median absolute deviation (MAD)
21.8 - Distribution of errors
21.9 - Assignment-3 Apply k-Nearest Neighbor
22.1 - Questions & Answers
23.1 - Conditional probability
23.10 - Bias and Variance tradeoff
23.11 - Feature importance and interpretability
23.12 - Imbalanced data
23.13 - Outliers
23.14 - Missing values
23.15 - Handling Numerical features (Gaussian NB)
23.16 - Multiclass classification
23.17 - Similarity or Distance matrix
23.18 - Large dimensionality
23.19 - Best and worst cases
23.2 - Independent vs Mutually exclusive events
23.20 - Code example
23.21 - Assignment-4 Apply Naive Bayes
23.22 - Revision Questions
23.3 - Bayes Theorem with examples
23.4 - Exercise problems on Bayes Theorem
23.5 - Naive Bayes algorithm
23.6 - Toy example Train and test stages
23.7 - Naive Bayes on Text data
23.8 - LaplaceAdditive Smoothing
23.9 - Log-probabilities for numerical stability
24.1 - Geometric intuition of Logistic Regression
24.10 - Column Standardization
24.11 - Feature importance and Model interpretability
24.12 - Collinearity of features
24.13 - TestRun time space and time complexity
24.14 - Real world cases
24.15 - Non-linearly separable data & feature engineering
24.16 - Code sample Logistic regression, GridSearchCV, RandomSearchCV
24.17 - Assignment-5 Apply Logistic Regression
24.18 - Extensions to Generalized linear models
24.2 - Sigmoid function Squashing
24.3 - Mathematical formulation of Objective function
24.4 - Weight vector
24.5 - L2 Regularization Overfitting and Underfitting
24.6 - L1 regularization and sparsity
24.7 - Probabilistic Interpretation Gaussian Naive Bayes
24.8 - Loss minimization interpretation
24.9 - hyperparameters and random search
25.1 - Geometric intuition of Linear Regression
25.2 - Mathematical formulation
25.3 - Real world Cases
25.4 - Code sample for Linear Regression
26.1 - Differentiation
26.10 - Logistic regression formulation revisited
26.11 - Why L1 regularization creates sparsity
26.12 - Assignment 6 Implement SGD for linear regression
26.13 - Revision questions
26.2 - Online differentiation tools
26.3 - Maxima and Minima
26.4 - Vector calculus Grad
26.5 - Gradient descent geometric intuition
26.6 - Learning rate
26.7 - Gradient descent for linear regression
26.8 - SGD algorithm
26.9 - Constrained Optimization & PCA
27.1 - Questions & Answers
28.1 - Geometric Intution
28.10 - Train and run time complexities
28.11 - nu-SVM control errors and support vectors
28.12 - SVM Regression
28.13 - Cases
28.14 - Code Sample
28.15 - Assignment-7 Apply SVM
28.16 - Revision Questions
28.2 - Mathematical derivation
28.3 - Why we take values +1 and and -1 for Support vector planes
28.4 - Loss function (Hinge Loss) based interpretation
28.5 - Dual form of SVM formulation
28.6 - kernel trick
28.7 - Polynomial Kernel
28.8 - RBF-Kernel
28.9 - Domain specific Kernels
29.1 - Questions & Answers
3.1 - Lists
3.2 - Tuples part 1
3.3 - Tuples part-2
3.4 - Sets
3.5 - Dictionary
3.6 - Strings
30.1 - Geometric Intuition of decision tree Axis parallel hyperplanes
30.10 - Overfitting and Underfitting
30.11 - Train and Run time complexity
30.12 - Regression using Decision Trees
30.13 - Cases
30.14 - Code Samples
30.15 - Assignment-8 Apply Decision Trees
30.16 - Revision Questions
30.2 - Sample Decision tree
30.3 - Building a decision TreeEntropy
30.4 - Building a decision TreeInformation Gain
30.5 - Building a decision Tree Gini Impurity
30.6 - Building a decision Tree Constructing a DT
30.7 - Building a decision Tree Splitting numerical features
30.8 - Feature standardization
30.9 - Building a decision TreeCategorical features with many possible values
31.1 - Questions & Answers
32.1 - What are ensembles
32.10 - Residuals, Loss functions and gradients
32.11 - Gradient Boosting
32.12 - Regularization by Shrinkage
32.13 - Train and Run time complexity
32.14 - XGBoost Boosting + Randomization
32.15 - AdaBoost geometric intuition
32.16 - Stacking models
32.17 - Cascading classifiers
32.18 - Kaggle competitions vs Real world
32.19 - Assignment-9 Apply Random Forests & GBDT
32.2 - Bootstrapped Aggregation (Bagging) Intuition
32.20 - Revision Questions
32.3 - Random Forest and their construction
32.4 - Bias-Variance tradeoff
32.5 - Train and run time complexity
32.6 - BaggingCode Sample
32.7 - Extremely randomized trees
32.8 - Random Tree Cases
32.9 - Boosting Intuition
33.1 - Introduction
33.10 - Indicator variables
33.11 - Feature binning
33.12 - Interaction variables
33.13 - Mathematical transforms
33.14 - Model specific featurizations
33.15 - Feature orthogonality
33.16 - Domain specific featurizations
33.17 - Feature slicing
33.18 - Kaggle Winners solutions
33.2 - Moving window for Time Series Data
33.3 - Fourier decomposition
33.4 - Deep learning features LSTM
33.5 - Image histogram
33.6 - Keypoints SIFT
33.7 - Deep learning features CNN
33.8 - Relational data
33.9 - Graph data
34.1 - Calibration of ModelsNeed for calibration
34.10 - AB testing
34.11 - Data Science Life cycle
34.12 - VC dimension
34.2 - Productionization and deployment of Machine Learning Models
34.3 - Calibration Plots
34.4 - Platt’s CalibrationScaling
34.5 - Isotonic Regression
34.6 - Code Samples
34.7 - Modeling in the presence of outliers RANSAC
34.8 - Productionizing models
34.9 - Retraining models periodically
35.1 - What is Clustering
35.10 - K-Medoids
35.11 - Determining the right K
35.12 - Code Samples
35.13 - Time and space complexity
35.14 - Assignment-10 Apply K-means, Agglomerative, DBSCAN clustering algorithms
35.2 - Unsupervised learning
35.3 - Applications
35.4 - Metrics for Clustering
35.5 - K-Means Geometric intuition, Centroids
35.6 - K-Means Mathematical formulation Objective function
35.7 - K-Means Algorithm
35.8 - How to initialize K-Means++
35.9 - Failure casesLimitations
36.1 - Agglomerative & Divisive, Dendrograms
36.2 - Agglomerative Clustering
36.3 - Proximity methods Advantages and Limitations
36.4 - Time and Space Complexity
36.5 - Limitations of Hierarchical Clustering
36.6 - Code sample
36.7 - Assignment-10 Apply K-means, Agglomerative, DBSCAN clustering algorithms
37.1 - Density based clustering
37.10 - Assignment-10 Apply K-means, Agglomerative, DBSCAN clustering algorithms
37.11 - Revision Questions
37.2 - MinPts and Eps Density
37.3 - Core, Border and Noise points
37.4 - Density edge and Density connected points
37.5 - DBSCAN Algorithm
37.6 - Hyper Parameters MinPts and Eps
37.7 - Advantages and Limitations of DBSCAN
37.8 - Time and Space Complexity
37.9 - Code samples
38.1 - Problem formulation Movie reviews
38.10 - Matrix Factorization for recommender systems Netflix Prize Solution
38.11 - Cold Start problem
38.12 - Word vectors as MF
38.13 - Eigen-Faces
38.14 - Code example
38.15 - Assignment-11 Apply Truncated SVD
38.16 - Revision Questions
38.2 - Content based vs Collaborative Filtering
38.3 - Similarity based Algorithms
38.4 - Matrix Factorization PCA, SVD
38.5 - Matrix Factorization NMF
38.6 - Matrix Factorization for Collaborative filtering
38.7 - Matrix Factorization for feature engineering
38.8 - Clustering as MF
38.9 - Hyperparameter tuning
39.1 - Questions & Answers
4.1 - Introduction
4.10 - Debugging Python
4.2 - Types of functions
4.3 - Function arguments
4.4 - Recursive functions
4.5 - Lambda functions
4.6 - Modules
4.7 - Packages
4.8 - File Handling
4.9 - Exception Handling
40.1 - BusinessReal world problem
40.10 - Data Modeling Multi label Classification
40.11 - Data preparation
40.12 - Train-Test Split
40.13 - Featurization
40.14 - Logistic regression One VS Rest
40.15 - Sampling data and tags+Weighted models
40.16 - Logistic regression revisited
40.17 - Why not use advanced techniques
40.18 - Assignments
40.2 - Business objectives and constraints
40.3 - Mapping to an ML problem Data overview
40.4 - Mapping to an ML problemML problem formulation
40.5 - Mapping to an ML problemPerformance metrics
40.6 - Hamming loss
40.7 - EDAData Loading
40.8 - EDAAnalysis of tags
40.9 - EDAData Preprocessing
41.1 - BusinessReal world problem Problem definition
41.10 - EDA Feature analysis
41.11 - EDA Data Visualization T-SNE
41.12 - EDA TF-IDF weighted Word2Vec featurization
41.13 - ML Models Loading Data
41.14 - ML Models Random Model
41.15 - ML Models Logistic Regression and Linear SVM
41.16 - ML Models XGBoost
41.17 - Assignments
41.2 - Business objectives and constraints
41.3 - Mapping to an ML problem Data overview
41.4 - Mapping to an ML problem ML problem and performance metric
41.5 - Mapping to an ML problem Train-test split
41.6 - EDA Basic Statistics
41.7 - EDA Basic Feature Extraction
41.8 - EDA Text Preprocessing
41.9 - EDA Advanced Feature Extraction
42.1 - Problem Statement Recommend similar apparel products in e-commerce using product descriptions and Images
42.10 - Text Pre-Processing Tokenization and Stop-word removal
42.11 - Stemming
42.12 - Text based product similarity Converting text to an n-D vector bag of words
42.13 - Code for bag of words based product similarity
42.14 - TF-IDF featurizing text based on word-importance
42.15 - Code for TF-IDF based product similarity
42.16 - Code for IDF based product similarity
42.17 - Text Semantics based product similarity Word2Vec(featurizing text based on semantic similarity)
42.18 - Code for Average Word2Vec product similarity
42.19 - TF-IDF weighted Word2Vec
42.2 - Plan of action
42.20 - Code for IDF weighted Word2Vec product similarity
42.21 - Weighted similarity using brand and color
42.22 - Code for weighted similarity
42.23 - Building a real world solution
42.24 - Deep learning based visual product similarityConvNets How to featurize an image edges, shapes, parts
42.25 - Using Keras + Tensorflow to extract features
42.26 - Visual similarity based product similarity
42.27 - Measuring goodness of our solution AB testing
42.28 - Exercise Build a weighted Nearest neighbor model using Visual, Text, Brand and Color
42.3 - Amazon product advertising API
42.4 - Data folders and paths
42.5 - Overview of the data and Terminology
42.6 - Data cleaning and understandingMissing data in various features
42.7 - Understand duplicate rows
42.8 - Remove duplicates Part 1
42.9 - Remove duplicates Part 2
43.1 - Businessreal world problem Problem definition
43.10 - ML models – using byte files only Random Model
43.11 - k-NN
43.12 - Logistic regression
43.13 - Random Forest and Xgboost
43.14 - ASM Files Feature extraction & Multiprocessing
43.15 - File-size feature
43.16 - Univariate analysis
43.17 - t-SNE analysis
43.18 - ML models on ASM file features
43.19 - Models on all features t-SNE
43.2 - Businessreal world problem Objectives and constraints
43.20 - Models on all features RandomForest and Xgboost
43.21 - Assignments
43.3 - Machine Learning problem mapping Data overview
43.4 - Machine Learning problem mapping ML problem
43.5 - Machine Learning problem mapping Train and test splitting
43.6 - Exploratory Data Analysis Class distribution
43.7 - Exploratory Data Analysis Feature extraction from byte files
43.8 - Exploratory Data Analysis Multivariate analysis of features from byte files
43.9 - Exploratory Data Analysis Train-Test class distribution
44.1 - BusinessReal world problemProblem definition
44.10 - Exploratory Data AnalysisCold start problem
44.11 - Computing Similarity matricesUser-User similarity matrix
44.12 - Computing Similarity matricesMovie-Movie similarity
44.13 - Computing Similarity matricesDoes movie-movie similarity work
44.14 - ML ModelsSurprise library
44.15 - Overview of the modelling strategy
44.16 - Data Sampling
44.17 - Google drive with intermediate files
44.18 - Featurizations for regression
44.19 - Data transformation for Surprise
44.2 - Objectives and constraints
44.20 - Xgboost with 13 features
44.21 - Surprise Baseline model
44.22 - Xgboost + 13 features +Surprise baseline model
44.23 - Surprise KNN predictors
44.24 - Matrix Factorization models using Surprise
44.25 - SVD ++ with implicit feedback
44.26 - Final models with all features and predictors
44.27 - Comparison between various models
44.28 - Assignments
44.3 - Mapping to an ML problemData overview
44.4 - Mapping to an ML problemML problem formulation
44.5 - Exploratory Data AnalysisData preprocessing
44.6 - Exploratory Data AnalysisTemporal Train-Test split
44.7 - Exploratory Data AnalysisPreliminary data analysis
44.8 - Exploratory Data AnalysisSparse matrix representation
44.9 - Exploratory Data AnalysisAverage ratings for various slices
45.1 - BusinessReal world problem Overview
45.10 - Univariate AnalysisVariation Feature
45.11 - Univariate AnalysisText feature
45.12 - Machine Learning ModelsData preparation
45.13 - Baseline Model Naive Bayes
45.14 - K-Nearest Neighbors Classification
45.15 - Logistic Regression with class balancing
45.16 - Logistic Regression without class balancing
45.17 - Linear-SVM
45.18 - Random-Forest with one-hot encoded features
45.19 - Random-Forest with response-coded features
45.2 - Business objectives and constraints
45.20 - Stacking Classifier
45.21 - Majority Voting classifier
45.22 - Assignments
45.3 - ML problem formulation Data
45.4 - ML problem formulation Mapping real world to ML problem
45.4 - ML problem formulation Mapping real world to ML problem#
45.5 - ML problem formulation Train, CV and Test data construction
45.6 - Exploratory Data AnalysisReading data & preprocessing
45.7 - Exploratory Data AnalysisDistribution of Class-labels
45.8 - Exploratory Data Analysis “Random” Model
45.9 - Univariate AnalysisGene feature
46.1 - BusinessReal world problem Overview
46.10 - Data Cleaning Speed
46.11 - Data Cleaning Distance
46.12 - Data Cleaning Fare
46.13 - Data Cleaning Remove all outlierserroneous points
46.14 - Data PreparationClusteringSegmentation
46.15 - Data PreparationTime binning
46.16 - Data PreparationSmoothing time-series data
46.17 - Data PreparationSmoothing time-series data cont
46.18 - Data Preparation Time series and Fourier transforms
46.19 - Ratios and previous-time-bin values
46.2 - Objectives and Constraints
46.20 - Simple moving average
46.21 - Weighted Moving average
46.22 - Exponential weighted moving average
46.23 - Results
46.24 - Regression models Train-Test split & Features
46.25 - Linear regression
46.26 - Random Forest regression
46.27 - Xgboost Regression
46.28 - Model comparison
46.29 - Assignment
46.3 - Mapping to ML problem Data
46.4 - Mapping to ML problem dask dataframes
46.5 - Mapping to ML problem FieldsFeatures
46.6 - Mapping to ML problem Time series forecastingRegression
46.7 - Mapping to ML problem Performance metrics
46.8 - Data Cleaning Latitude and Longitude data
46.9 - Data Cleaning Trip Duration
47.1 - History of Neural networks and Deep Learning
47.10 - Backpropagation
47.11 - Activation functions
47.12 - Vanishing Gradient problem
47.13 - Bias-Variance tradeoff
47.14 - Decision surfaces Playground
47.2 - How Biological Neurons work
47.3 - Growth of biological neural networks
47.4 - Diagrammatic representation Logistic Regression and Perceptron
47.5 - Multi-Layered Perceptron (MLP)
47.6 - Notation
47.7 - Training a single-neuron model
47.8 - Training an MLP Chain Rule
47.9 - Training an MLPMemoization
48.1 - Deep Multi-layer perceptrons1980s to 2010s
48.10 - Nesterov Accelerated Gradient (NAG)
48.11 - OptimizersAdaGrad
48.12 - Optimizers Adadelta andRMSProp
48.13 - Adam
48.14 - Which algorithm to choose when
48.15 - Gradient Checking and clipping
48.16 - Softmax and Cross-entropy for multi-class classification
48.17 - How to train a Deep MLP
48.18 - Auto Encoders
48.19 - Word2Vec CBOW
48.2 - Dropout layers & Regularization
48.20 - Word2Vec Skip-gram
48.21 - Word2Vec Algorithmic Optimizations
48.3 - Rectified Linear Units (ReLU)
48.4 - Weight initialization
48.5 - Batch Normalization
48.6 - OptimizersHill-descent analogy in 2D
48.7 - OptimizersHill descent in 3D and contours
48.8 - SGD Recap
48.9 - Batch SGD with momentum
49.1 - Tensorflow and Keras overview
49.10 - Model 3 Batch Normalization
49.11 - Model 4 Dropout
49.12 - MNIST classification in Keras
49.13 - Hyperparameter tuning in Keras
49.14 - Exercise Try different MLP architectures on MNIST dataset
49.2 - GPU vs CPU for Deep Learning
49.3 - Google Colaboratory
49.4 - Install TensorFlow
49.5 - Online documentation and tutorials
49.6 - Softmax Classifier on MNIST dataset
49.7 - MLP Initialization
49.8 - Model 1 Sigmoid activation
49.9 - Model 2 ReLU activation
5.1 - Numpy Introduction
5.2 - Numerical operations on Numpy
50.1 - Biological inspiration Visual Cortex
50.10 - Data Augmentation
50.11 - Convolution Layers in Keras
50.12 - AlexNet
50.13 - VGGNet
50.14 - Residual Network
50.15 - Inception Network
50.16 - What is Transfer learning
50.17 - Code example Cats vs Dogs
50.18 - Code Example MNIST dataset
50.19 - Assignment Try various CNN networks on MNIST dataset#
50.2 - ConvolutionEdge Detection on images
50.3 - ConvolutionPadding and strides
50.4 - Convolution over RGB images
50.5 - Convolutional layer
50.6 - Max-pooling
50.7 - CNN Training Optimization
50.8 - Example CNN LeNet [1998]
50.9 - ImageNet dataset
51.1 - Why RNNs
51.10 - Code example IMDB Sentiment classification
51.11 - Exercise Amazon Fine Food reviews LSTM model
51.2 - Recurrent Neural Network
51.3 - Training RNNs Backprop
51.4 - Types of RNNs
51.5 - Need for LSTMGRU
51.6 - LSTM
51.7 - GRUs
51.8 - Deep RNN
51.9 - Bidirectional RNN
52.1 - Questions and Answers
53.1 - Self Driving Car Problem definition
53.10 - NVIDIA’s end to end CNN model
53.11 - Train the model
53.12 - Test and visualize the output
53.13 - Extensions
53.14 - Assignment
53.2 - Datasets
53.2 - Datasets#
53.3 - Data understanding & Analysis Files and folders
53.4 - Dash-cam images and steering angles
53.5 - Split the dataset Train vs Test
53.6 - EDA Steering angles
53.7 - Mean Baseline model simple
53.8 - Deep-learning modelDeep Learning for regression CNN, CNN+RNN
53.9 - Batch load the dataset
54.1 - Real-world problem
54.10 - MIDI music generation
54.11 - Survey blog
54.2 - Music representation
54.3 - Char-RNN with abc-notation Char-RNN model
54.4 - Char-RNN with abc-notation Data preparation
54.5 - Char-RNN with abc-notationMany to Many RNN ,TimeDistributed-Dense layer
54.6 - Char-RNN with abc-notation State full RNN
54.7 - Char-RNN with abc-notation Model architecture,Model training
54.8 - Char-RNN with abc-notation Music generation
54.9 - Char-RNN with abc-notation Generate tabla music
55.1 - Human Activity Recognition Problem definition
55.2 - Dataset understanding
55.3 - Data cleaning & preprocessing
55.4 - EDAUnivariate analysis
55.5 - EDAData visualization using t-SNE
55.6 - Classical ML models
55.7 - Deep-learning Model
55.8 - Exercise Build deeper LSTM models and hyper-param tune them
56.1 - Problem definition
56.10 - Feature engineering on GraphsJaccard & Cosine Similarities
56.11 - PageRank
56.12 - Shortest Path
56.13 - Connected-components
56.14 - Adar Index
56.15 - Kartz Centrality
56.16 - HITS Score
56.17 - SVD
56.18 - Weight features
56.19 - Modeling
56.2 - Overview of Graphs nodevertex, edgelink, directed-edge, path
56.3 - Data format & Limitations
56.4 - Mapping to a supervised classification problem
56.5 - Business constraints & Metrics
56.6 - EDABasic Stats
56.7 - EDAFollower and following stats
56.8 - EDABinary Classification Task
56.9 - EDATrain and test split
57.1 - Introduction to Databases
57.10 - ORDER BY
57.11 - DISTINCT
57.12 - WHERE, Comparison operators, NULL
57.13 - Logical Operators
57.14 - Aggregate Functions COUNT, MIN, MAX, AVG, SUM
57.15 - GROUP BY
57.16 - HAVING
57.17 - Order of keywords#
57.18 - Join and Natural Join
57.19 - Inner, Left, Right and Outer joins
57.2 - Why SQL
57.20 - Sub QueriesNested QueriesInner Queries
57.21 - DMLINSERT
57.22 - DMLUPDATE , DELETE
57.23 - DDLCREATE TABLE
57.24 - DDLALTER ADD, MODIFY, DROP
57.25 - DDLDROP TABLE, TRUNCATE, DELETE
57.26 - Data Control Language GRANT, REVOKE
57.27 - Learning resources
57.3 - Execution of an SQL statement
57.4 - IMDB dataset
57.5 - Installing MySQL
57.6 - Load IMDB data
57.7 - USE, DESCRIBE, SHOW TABLES
57.8 - SELECT
57.9 - LIMIT, OFFSET
58.1 - AD-Click Predicition
59.1 - Revision Questions
59.2 - Questions
59.3 - External resources for Interview Questions
6.1 - Getting started with Matplotlib
7.1 - Getting started with pandas
7.2 - Data Frame Basics
7.3 - Key Operations on Data Frames
8.1 - Space and Time Complexity Find largest number in a list
8.2 - Binary search
8.3 - Find elements common in two lists
8.4 - Find elements common in two lists using a HashtableDict
9.1 - Introduction to IRIS dataset and 2D scatter plot
9.10 - Percentiles and Quantiles
9.11 - IQR(Inter Quartile Range) and MAD(Median Absolute Deviation)
9.12 - Box-plot with Whiskers
9.13 - Violin Plots
9.14 - Summarizing Plots, Univariate, Bivariate and Multivariate analysis
9.15 - Multivariate Probability Density, Contour Plot
9.16 - Exercise Perform EDA on Haberman dataset
9.2 - 3D scatter plot
9.3 - Pair plots
9.4 - Limitations of Pair Plots
9.5 - Histogram and Introduction to PDF(Probability Density Function)
9.6 - Univariate Analysis using PDF
9.7 - CDF(Cumulative Distribution Function)
9.8 - Mean, Variance and Standard Deviation
9.9 - Median
also You can watch my other last: Programming-posts
Screenshots
AppliedAICourse - Applied Machine Learning Course
AppliedAICourse - Applied Machine Learning Course
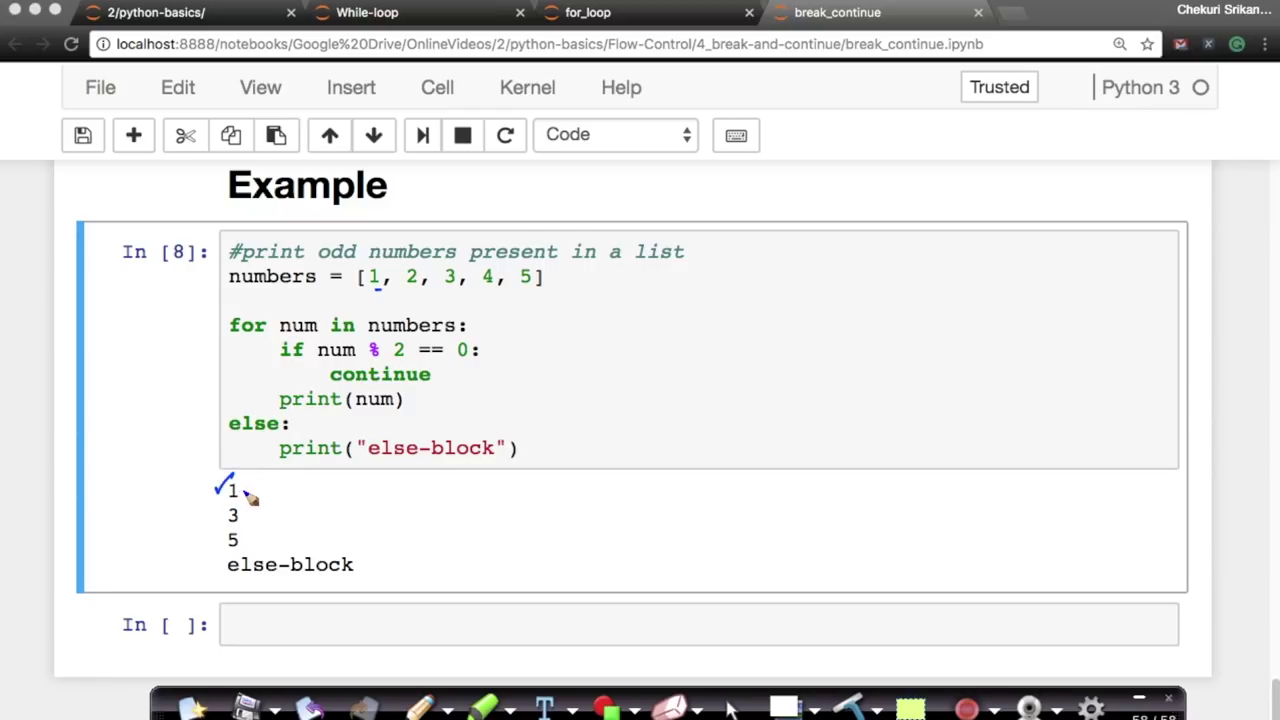
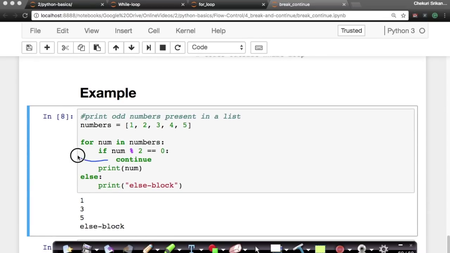
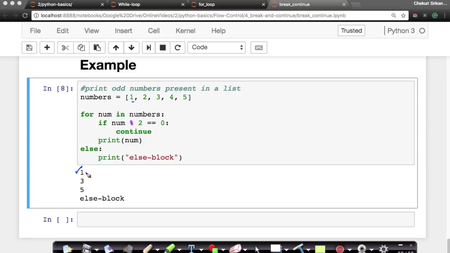
AppliedAICourse - Applied Machine Learning Course
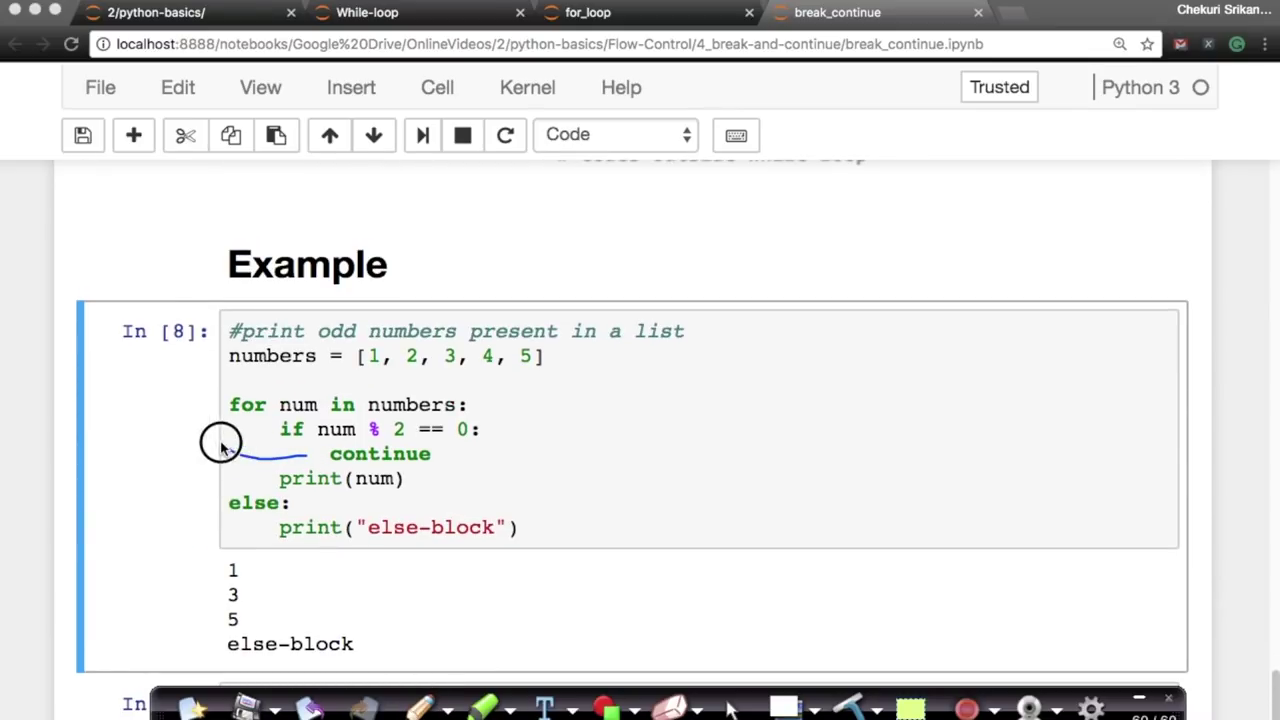
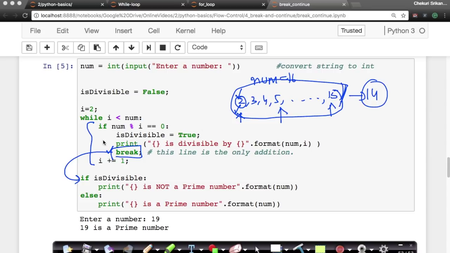
AppliedAICourse - Applied Machine Learning Course
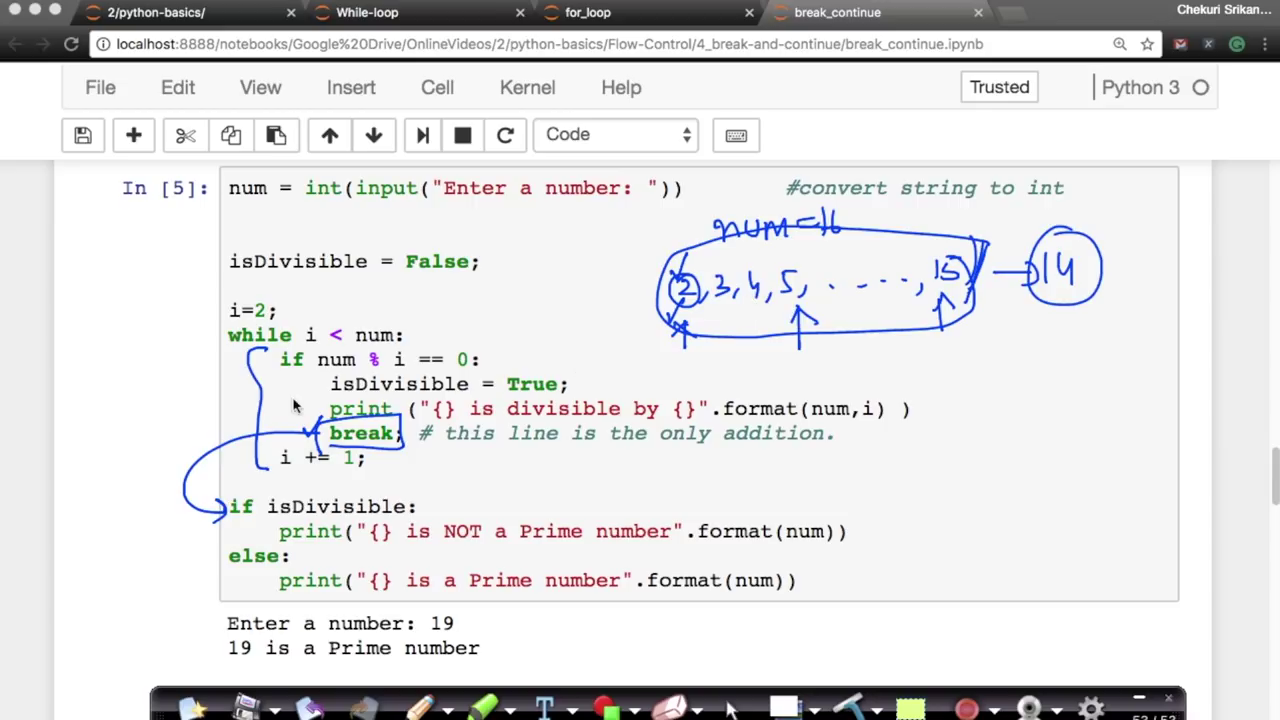
AppliedAICourse - Applied Machine Learning Course
Exclusive eLearning Videos ParRus-blog ← add to bookmarks

AppliedAICourse - Applied Machine Learning Course
