Learn Spark and Hadoop Overnight on GCP

Learn Spark and Hadoop Overnight on GCP
.MP4, AVC, 900 kbps, 1280x720 | English, AAC, 128 kbps, 2 Ch | 3h 35m | 817 MB
Instructor: CS Viz
.MP4, AVC, 900 kbps, 1280x720 | English, AAC, 128 kbps, 2 Ch | 3h 35m | 817 MB
Instructor: CS Viz
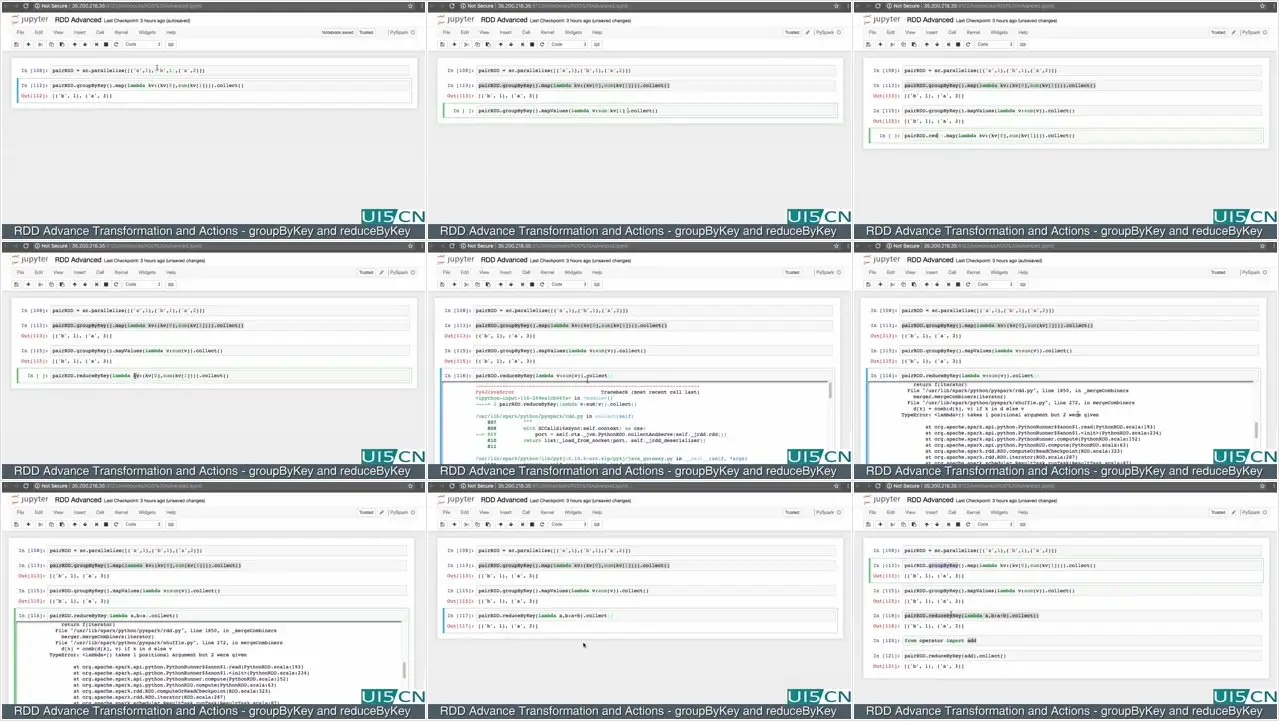
This is a comprehensive hands-on course on Spark Hadoop
In this course, we focused on Big Data and open source solutions around that.
We require these tools for our E-commerce end of Project CORE (Create your Own Recommendation Engine) is one of its kind of project to learn technology End-to-End
We will explore Hadoop one of the prominent Big Data solution
We will look Why part and How part of it and its ecosystem, its Architecture and basic inner working and will also spin our first Hadoop under 2 min in Google Cloud
This particular course we are going to use in Project CORE which is comprehensive project on hands on technologies. In Project CORE you will learn more about Building you own system on Big Data, Spark, Machine Learning, SAPUI5, Angular4, D3JS, SAP® HANA®
With this Course you will get a brief understanding on Apache Spark™, Which is a fast and general engine for large-scale data processing.
Spark is used in Project CORE to manage Big data with HDFS file system, We are storing 1.5 million records of books in spark and implementing collaborative filtering algorithm.
Spark offers over 80 high-level operators that make it easy to build parallel apps. And you can use it interactively from the Scala, Python and R shells.
Spark powers a stack of libraries including SQL and DataFrames, MLlib for machine learning, GraphX, and Spark Streaming. You can combine these libraries seamlessly in the same application.
Runs Everywhere - Spark runs on Hadoop, Mesos, standalone, or in the cloud.
Learn Spark and Hadoop Overnight on GCP