

Data Engineering With Google Datafusion And Big Query (Cdap)
Data Engineering With Google Datafusion And Big Query (Cdap)
Published 5/2023
MP4 | Video: h264, 1280x720 | Audio: AAC, 44.1 KHz
Language: English | Size: 2.03 GB | Duration: 3h 7m
Published 5/2023
MP4 | Video: h264, 1280x720 | Audio: AAC, 44.1 KHz
Language: English | Size: 2.03 GB | Duration: 3h 7m
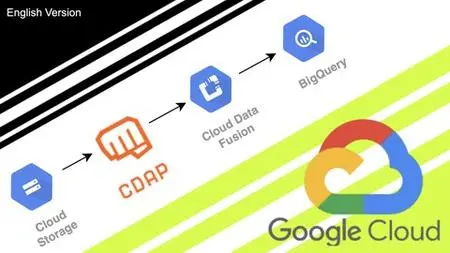
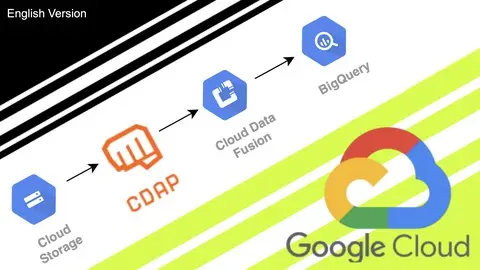
Your first steps in Data Engineering with Google Datafusion, a low-code tool with an open-source version (CDAP)
What you'll learn
Understand a bit more Google Cloud Resources
Use Google Datafusion as ETL tool
Data Engineering Low Code
ETL
Create Data Pipelines and DAGs
Read and Write data on Google Big Query
Read and Write data on Google Cloud Storage
Data Transformations with low code and queries
Requirements
GCP account
Previous exposure to SQL
Description
This is an INTRODUCTORY course to Google Cloud's low-code ingestion tool, Datafusion. Google Data Fusion is a fully managed data integration platform that allows data engineers to efficiently create, deploy, and manage data pipelines.One of the main reasons to use Google Data Fusion is its ease of use. With an intuitive and visual interface, data engineers can create complex data pipelines without the need for extensive coding. The drag-and-drop interface simplifies the process of data transformation and cleansing, allowing professionals to focus on business logic rather than worrying about detailed coding.Another significant benefit of Google Data Fusion is its scalability. The platform runs on Google Cloud, which means it can handle large volumes of data and high-performance parallel processing. Data engineers can vertically or horizontally expand their processing capabilities according to project needs, ensuring they can handle any data demand at scale.Furthermore, Google Data Fusion seamlessly integrates with other services and products in the Google Cloud ecosystem. Data engineers can easily connect and integrate data pipelines with services such as BigQuery, Cloud Storage, Pub/Sub, and many others. This enables a cohesive and unified data architecture, facilitating data ingestion, storage, and analysis across multiple platforms.In this course, you will learn:Understanding its internal workings.What its benefits are.How to create a Datafusion instance.Using Google Cloud Storage as data input.Using BigQuery as a Data Lake (Bronze and Silver layers).Advanced features of BigQuery: Partitioned tables and MERGE command.Ingesting data from different sources.Transforming data with Wrangle (low code) and queries.Creating DAGs for data ETL (Extract, Transform, Load) and dependencies.Scheduling and inter-DAG dependencies.
Overview
Section 1: Introduction
Lecture 1 1.1 Get to Know the Teacher
Lecture 2 1.2 Get to Know the Course
Lecture 3 1.3 Introduction to Google Datafusion
Lecture 4 1.4 Architecture and Components
Lecture 5 1.5 Creating a Datafusion Instance
Lecture 6 1.6 Instance Types and Pricing
Lecture 7 1.7 Understanding a Datafusion Instance
Section 2: Developing Data Pipelines
Lecture 8 2.1 GCS Object Storage
Lecture 9 2.2 Big Query as Datalake
Lecture 10 2.3 Working with Semi Structured Data
Lecture 11 2.4 Pipeline Studio and Wangler
Lecture 12 2.5 Preview and Debug
Lecture 13 2.6 Sinking data on Big Query
Lecture 14 ERROR - Importing json pipeline from other Datafusion Instance
Lecture 15 2.7 Branching the Pipeline
Lecture 16 2.8 Move files
Lecture 17 2.9 Big Query as Source
Lecture 18 2.10 Transforming Data with Wrangler 1
Lecture 19 2.11 Transforming Data with Wrangler 2
Lecture 20 2.12 Transforming Data with Big Query
Lecture 21 2.13 Execute Query in Datafusion
Lecture 22 2.14 Data Partitioning in Big Query
Lecture 23 2.15 MERGE statement
Lecture 24 2.16 Delete temp Tables
Lecture 25 2.17 Scheduling and Pipeline Dependencies
Lecture 26 2.18 ERRO - Quota DISKS_TOTAL_GB Exceed
Lecture 27 2.19 Challenge
Data Engineers,Data Analysts,Data Scientists,Analytics Engineer