Big Data Analytics with Hadoop and Apache Spark

Big Data Analytics with Hadoop and Apache Spark
.MP4, AVC, 1280x720, 30 fps | English, AAC, 2 Ch | 1h 1m | 143 MB
Instructor: Kumaran Ponnambalam
.MP4, AVC, 1280x720, 30 fps | English, AAC, 2 Ch | 1h 1m | 143 MB
Instructor: Kumaran Ponnambalam
Apache Hadoop was a pioneer in the world of big data technologies, and it continues to be a leader in enterprise big data storage. Apache Spark is the top big data processing engine and provides an impressive array of features and capabilities. When used together, the Hadoop Distributed File System (HDFS) and Spark can provide a truly scalable big data analytics setup. In this course, learn how to leverage these two technologies to build scalable and optimized data analytics pipelines. Instructor Kumaran Ponnambalam explores ways to optimize data modeling and storage on HDFS; discusses scalable data ingestion and extraction using Spark; and provides tips for optimizing data processing in Spark. Plus, he provides a use case project that allows you to practice your new techniques.
Topics include:
Data modeling for analytics
Best practices for HDFS data storage
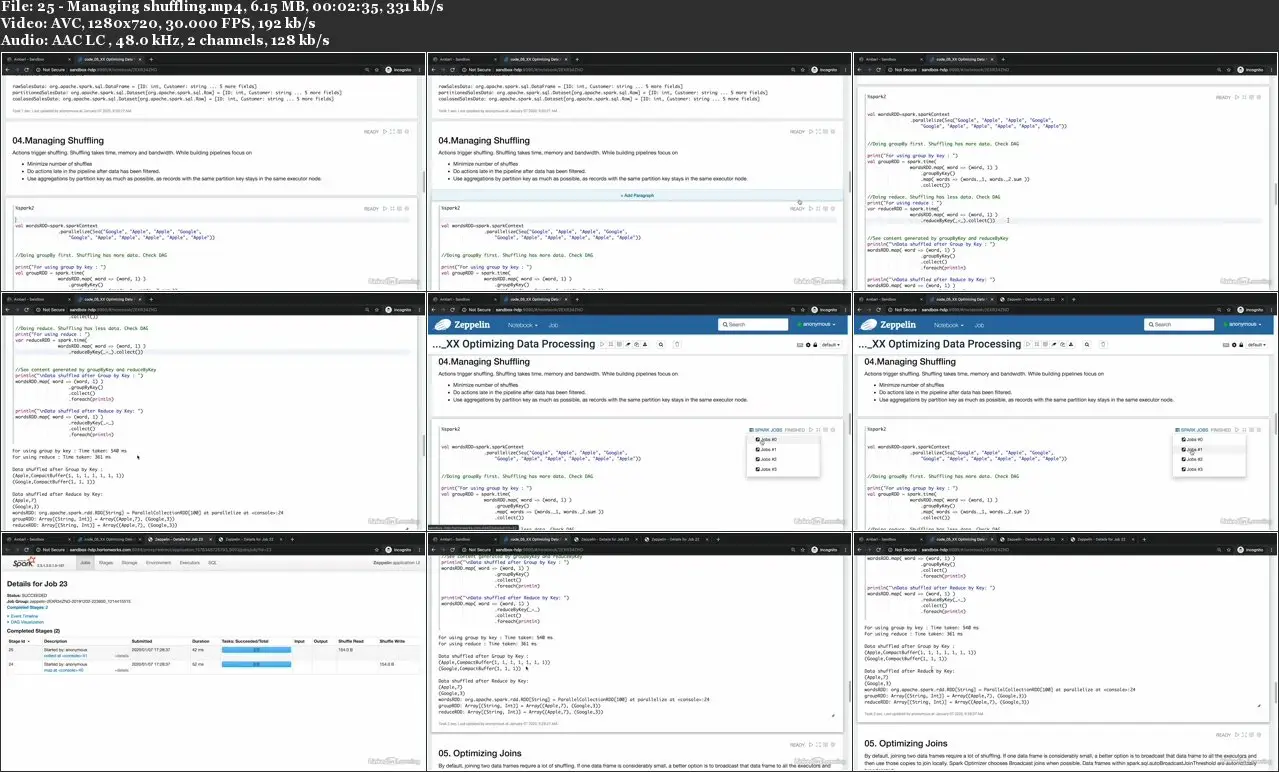
Ingesting and extracting data with Spark
Effectively managing partitions
Improving the join process
Best practices for optimizing Spark processing
Big Data Analytics with Hadoop and Apache Spark