Introduction to Parallel Programming using GPGPU and CUDA

Introduction to Parallel Programming using GPGPU and CUDA
MP4 | Video: AVC 1280x720 | Audio: AAC 44KHz 2ch | Duration: 1.5 Hours | Lec: 22 | 213 MB
Genre: eLearning | Language: English
MP4 | Video: AVC 1280x720 | Audio: AAC 44KHz 2ch | Duration: 1.5 Hours | Lec: 22 | 213 MB
Genre: eLearning | Language: English
Learn the fundamentals of GPU & CUDA programming, use your knowledge in Machine Learning, Data Mining and Deep Learning
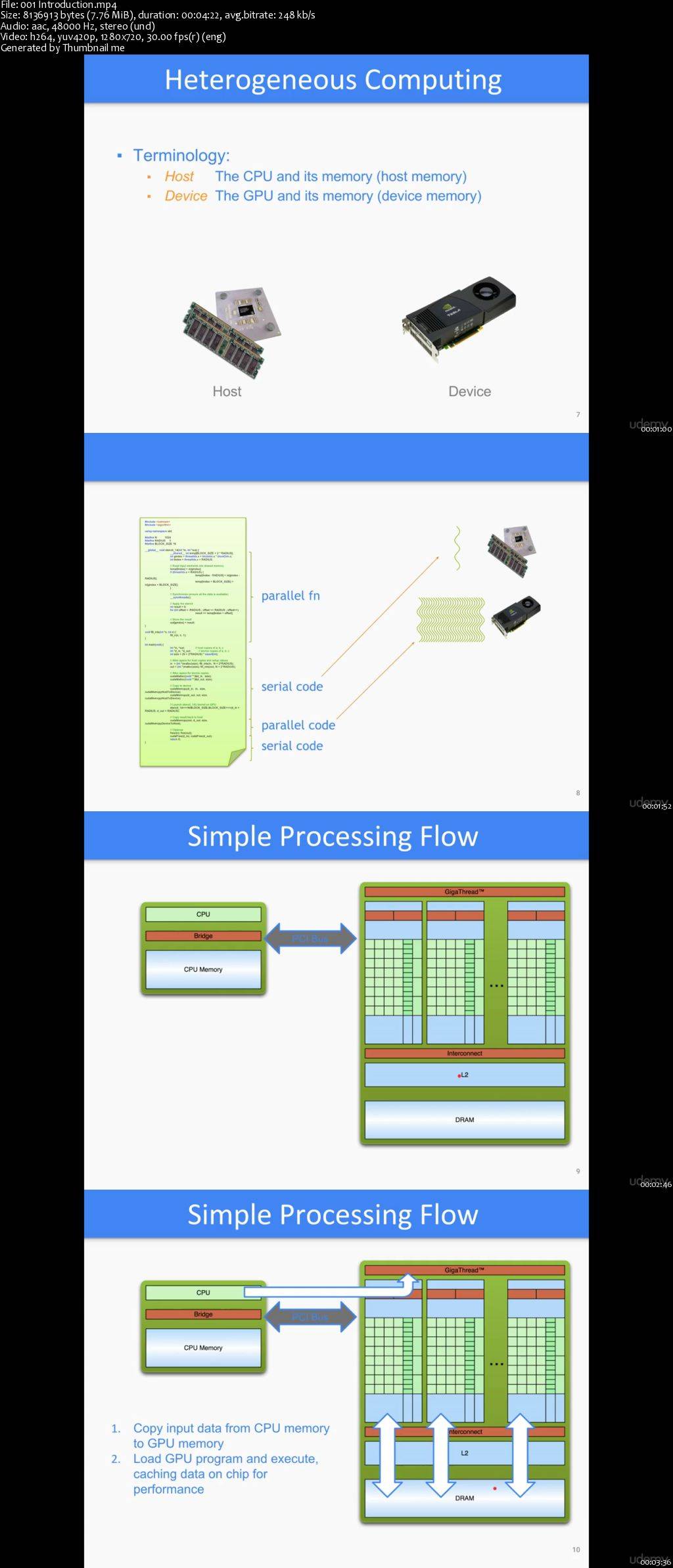
The first course on the Udemy platform to introduce the NVIDIA's CUDA parallel architecture and programming model. CUDA is a parallel computing platform and application programming interface (API) model created by Nvidia. When it was first introduced, the name was an acronym for Compute Unified Device Architecture, but now it's only called CUDA.
CUDA has several advantages over traditional general-purpose computation on GPUs (GPGPU) using graphics APIs: Scattered reads, Unified virtual memory (CUDA 4.0 and above), Unified memory (CUDA 6.0 and above), Shared memory, faster downloads and readbacks to and from the GPU, full support for integer and bitwise operations, including integer texture lookups.
The CUDA platform is designed to work with programming languages such as C, C++, and Fortran. It has wrappers for many other languages including Python, Java and so on. This accessibility makes it easier for specialists in parallel programming to use GPU resources, in contrast to prior APIs like Direct3D and OpenGL, which required advanced skills in graphics programming.
Also, CUDA supports programming frameworks such as OpenACC and OpenCL. CUDA is a freeware, works on Windows, Linux and Mac OSX. This course is intends to explain the basics of CUDA using C/C++ programming language, which you can use your stepping stone to machine learning, deep learning and big data careers.
Introduction to Parallel Programming using GPGPU and CUDA